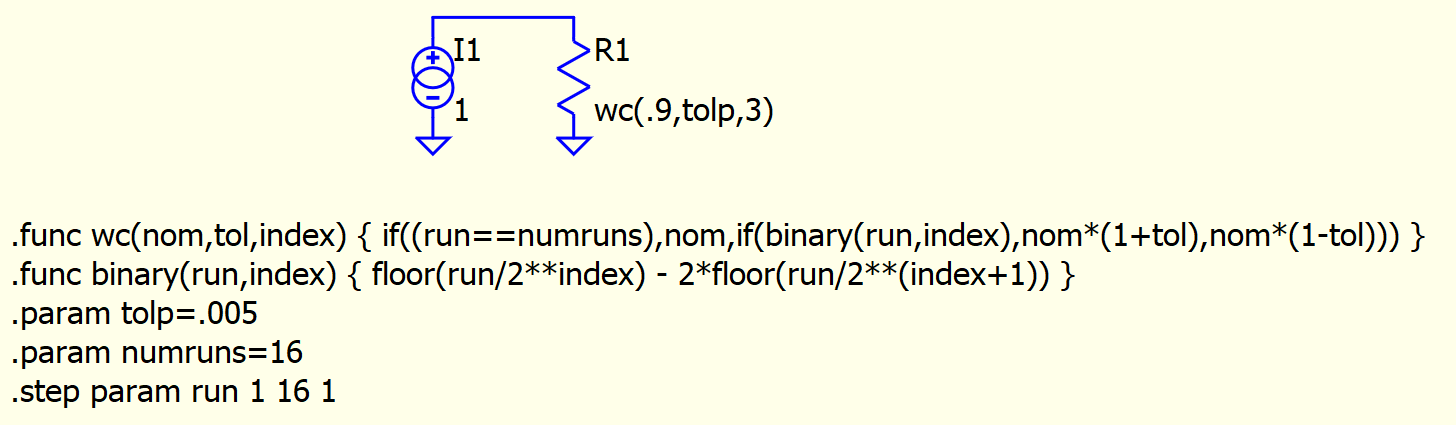
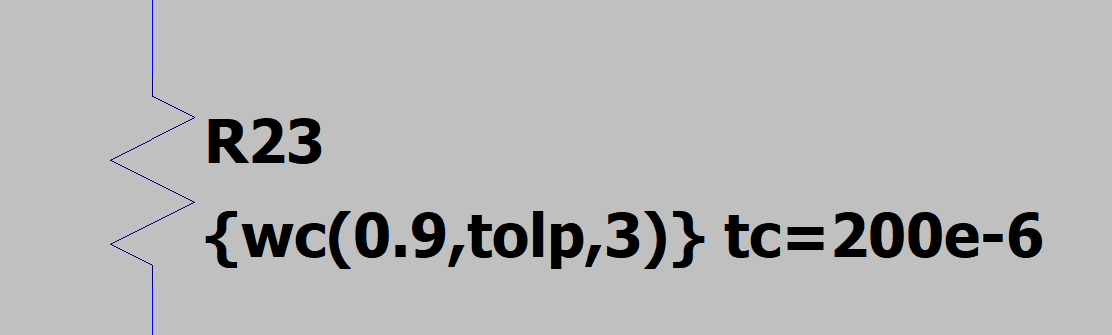That should all work in QSPICE, except QSPICE follows PSpice documentation which has curly braces , e.g., .func square(x) { x * x }. I think I can relax the requirement for curly braces since the syntax is otherwise distinguishable. Anyway, this compiles and runs:
I hadn’t implemented any of that because I’ve always felt that Monte Carlo was a gimmick. It’s just never been a design technique I’ve found useful even though all the design I did was ultra high rel stuff. And it’s hard to be on the mfg side and promote Monte Carlo as a responsible adult because it’s so unlikely to find production scatter included in models.
But EDA companies like Monte Carlo because it’s a great business models. They write a bunch of random numbers and people to pay for them! What could be better?
Not every feels that way about Monte Carlo, so today I added Random() and Gauss(sigma). Random() is a flat distribution from 0 to 1. Note that the flat distribution is more useful because (i) parts are sorted, meaning the scatter in a bin is flat and (ii) they exercise the scatter quicker. Gauss I did as a curiosity. I think I found numerically exact means of generating a Gaussian distribution which I’ve not otherwise heard of.
Thank you Mike…
Probably I`m wrong but any “component sensitivity” analysis highly dependent
on manufacturing and testing process. For good results we need to know distribution data from manufacturer. AFAIK resistors is not (not always) have a Gauss distribution. Am I right?
Yes, there is absolutely nothing like knowing. Of course, you have to know not only the distribution of a bunch of components but the distribution over many lots of components, which makes the data quite hard to gather since it takes a lot of time to get components from many lots. Short of knowing, Gaussian gets widely assumed because (i) it’s simple (ii) seems what they did in statistics class, and (iii) has a clean theoretical basis in the random walk problem, not because the distribution is known to be Gaussian. The distributions I’ve seen in measuration of physical data of unsorted events tends to look more like a Lorentzian, i.e., tails that die off much slower than Gaussian. It’s like the 1/f noise issue, it’s always 1/f but usually for different reasons.
If I did Monte Carlo, I would only ever use a flat distribution. The parts are either in spec or not.
The context there is that, as a design style, I don’t do Monte Carlo because I feel (i) I’m better off studying the impact of the critical components and (ii) if I don’t know which are the critical components, I don’t understand the circuit well enough move the circuit further along the design flow. That was my style for hi rel circuits. But showing that one did Monte Carlo might mitigate liability claw back if the circuit fails or kills someone, but for me, it hasn’t been the part of the design flow that gets things done or makes things better, nor is it is usually possible to get an accurate result since having the distribution is unlikely.
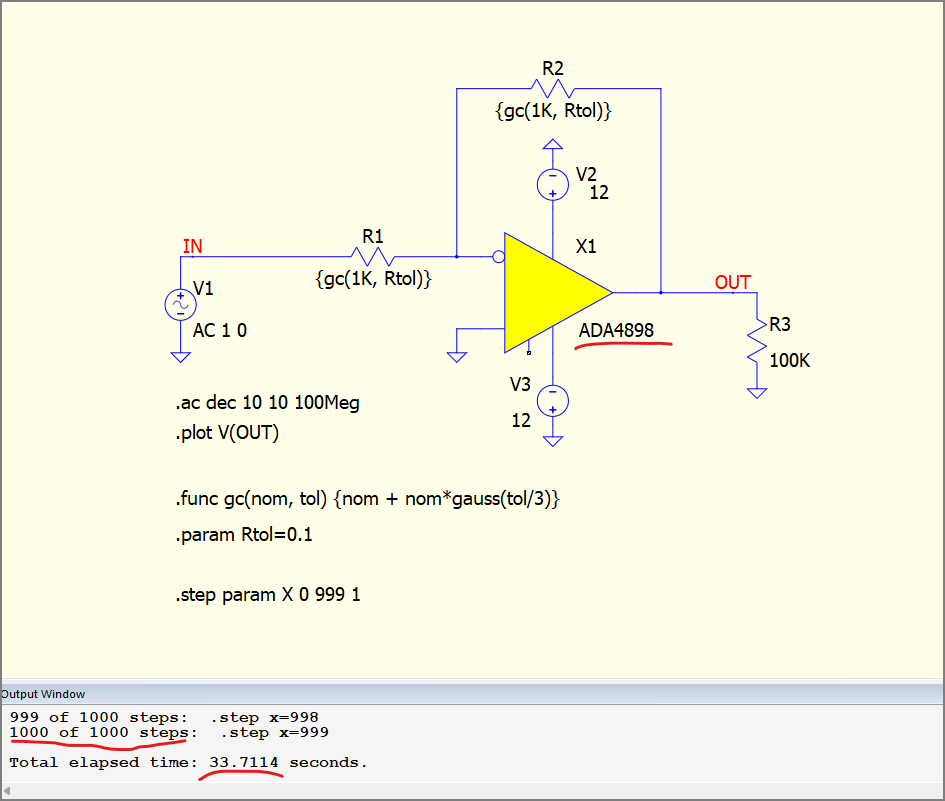
It took 33.7 seconds because the simulation process has to slowly dribble text to that console in the GUI process. That’s the time it would take for merely a .op of a sole voltage source.
Many years ago, I invented a simple and robust scheme for ranking components by their effects on Monte Carlo results. It can be based on any response or collection of responses and it assigns a number from 0 to 1 to every component parameter. It can also be programmed to assign values to expressions involving component vallue, e.g, voltage division ratios, time constabts, corner frequencies, quality factors, DC gain,… In the past, I’ve used it to diagnose sources of ampliier ringing and to specify RF transistors.
Disclaimer (included in the hope that it will earn your trust in my claims):
I don’t completely agree with Mike’s assessment of Monte Carlo but I caution against over-reliance on its precise numerical results. For one thing, it’s virtually impossible to accuately characterize component statistics. There are simply roo many variables to account for. Another consideration is the unknown factors that are excluded from the simulated circuit including parasitics, thermal effects, EMI,
Lastly, I would point out that every numeric determined by Monte Carlo analysis is a statistic. Mean values and spreads for any calculated circuit response are, themselves, random numbers. Different Monte Carlo runs will produce different result statistics (unless the exact same sequebce of component values is used). To be used rigorously, a Monte Carlo analysis would have to be repeated N times with the results averaged - where N is on the same order as the number of random samples taken for each Monte Carlo run.
This is not to say that Monte Carlo is useless. Just a caution against believing that the numbers you get are exact predictions of reality.